无处不在的缓存,究竟有何作用?(3)
|
另一个白色矩形表示 1 级指令高速缓存,大小也为 32 kB。顾名思义,该命令存储了各种命令,这些命令可以分解成较小的所谓的微操作(通常标记为μop),以供 ALU 执行。它们也有一个缓存,您可以将其归类为 0 级,因为它比 L1 缓存小(仅进行 1,500 次操作)并且更近。 您可能想知道为什么这些 SRAM 块这么小?为什么它们不是一兆字节大小?数据和指令高速缓存一起占用的芯片空间几乎与主要逻辑单元占用的空间相同,因此使其增大将增加芯片的整体尺寸。
但是它们仅保留几 kB 的主要原因是,随着内存容量的增大,查找和检索数据所需的时间也会增加。L1 高速缓存必须达到真正意义上的快,因此必须在大小和速度之间达成折衷 - 最多需要大约 5 个时钟周期(较长的浮点值)才能从该高速缓存中获取数据,以备使用。 但是,如果这是处理器内部唯一的缓存,则其性能将突然崩溃。这就是为什么它们都在内核中内置了另一级内存的原因:二级缓存。这是一个通用的存储块,保存着指令和数据。 它总是比级别 1 大很多:AMD Zen 2 处理器的最大容量为 512 kB,因此可以保持较低级别的缓存的良好供应。但是,这种额外的大小需要付出一定的代价,而与 1 级相比,从此缓存中查找和传输数据大约要花费两倍的时间。 追溯到最初的 Intel Pentium 时代,Level 2 高速缓存是一个单独的芯片,其位于小型插入式电路板上(例如RAMDIMM)或内置在主板中。最终它像奔腾 III 和 AMD K6-III 处理器一样,一直运用于 CPU 封装本身,直到最终被集成到 CPU 裸片中。
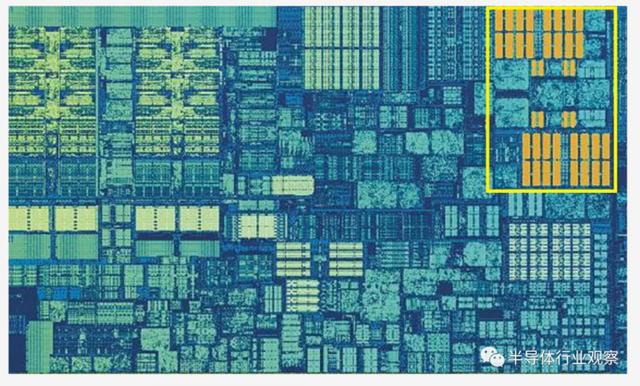
由于多核芯片的兴起,这项发展很快之后又有了另一个级别的缓存,以支持其他较低的级别。 上图是 Intel Kaby Lake 芯片,其左中间有 4 个内核(集成 GPU 占据了右侧一半的裸片)。每个内核都有其自己的“专用”组 1 级和 2 级缓存(白色和黄色高亮显示),但它们也带有第三组 SRAM 块。 3 级高速缓存即使直接围绕一个内核也可以与其他内核完全共享 - 每个都可以自由访问另一个 L3 高速缓存的内容。它 内存更大(在 2 到 32 MB 之间),但也慢得多,平均超过 30 个周期(尤其是在内核需要使用相距一定距离的缓存块中的数据时)。
在下面,我们可以看到 AMD Zen 2 架构中的单核:白色的 32 kB 1 级数据和指令缓存,黄色的 512 KB 2 级缓存和红色的 4 MB 巨大块 L3 缓存。 不只是一个数字: 高速缓存两个环节:其一是来提高性能通过加速向逻辑单元的数据传输,其二是保留常用指令和数据的副本。缓存中存储的信息分为两部分:数据本身以及它最初位于系统内存 / 存储中的位置。此地址称为缓存标签。 当 CPU 运行要从内存读取数据或向内存写入数据的操作时,它首先检查 1 级缓存中的变量。如果存在所需的数据(缓存命中),则几乎可以立即访问该数据。当所需标签不在最低缓存级别中时,即缓存未命中。 因此,在 L1 高速缓存中会有一个新标签,其余的处理器体系结构将接管,尽数浏览其他高速缓存级别(如有必要,一直返回主存储驱动器)以查找该标签的数据。但是要在 L1 缓存中为该新标签腾出空间,必须将其他内容始终引导到 L2 中。 这导致了几乎恒定的数据改组,所有这些都只需要几个时钟周期即可实现。实现此目的的唯一方法是在 SRAM 周围构建一个复杂的结构,以处理数据管理。换句话说,如果一个 CPU 内核仅由一个 ALU 组成,则 L1 缓存会简单得多,但是由于 ALU 有数十个(其中许多将处理两个指令线程),因此缓存需要多个连接来保持一切都在进行中。
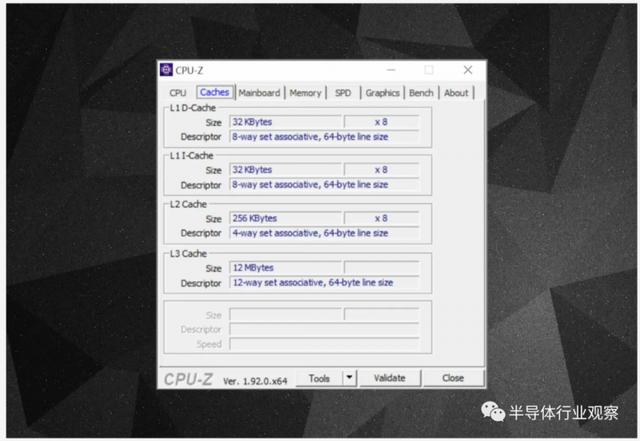
您可以使用免费程序(例如 CPU-Z)来检查为自己的计算机供电的处理器的缓存信息。但是所有这些信息意味着什么?一个重要的元素是关联的标签集。这与规则有关,这些规则取决于由系统内存中的数据块复制到缓存的方式。 上面的缓存信息适用于 Intel Core i7-9700K。它的 1 级高速缓存每个都分成 64 个小块,称为集合,并且每个小块进一步划分为高速缓存行(大小为 64 字节)。集相关意味着将来自系统内存的数据块映射到一个特定集合中的高速缓存行上,而不是自由地在任何地方进行映射。 8 向告诉我们,一个块可以与一组中的 8 条缓存行关联。关联性级别越高(即“方式”越多),则当 CPU 搜寻数据时,命中高速缓存的机会就越大,并且减少由高速缓存未命中引起的损失。缺点是它增加了复杂性,增加了功耗,还可能降低性能,因为有更多的缓存行要处理一个数据块。
高速缓存复杂性的另一方面在于如何在各个级别上保留数据。规则是在包含策略中设置的。例如,英特尔酷睿处理器具有完全包含的 L1 + L3 缓存。例如,这意味着第 1 级中的相同数据也可以在第 3 级中。这似乎在浪费宝贵的缓存空间,但是好处是,如果处理器在搜索低级标签时出错,数据就会丢失,而不需要遍历更高的级别来找到它。 在同一处理器中,L2 缓存是非包含性的:存储在其中的任何数据都不会复制到任何其他级别。这样可以节省空间,但确实会导致芯片的存储系统必须搜索 L3 以找到丢失的标签(实际上总会比这个更大一些)。受害者缓存与此类似,但是它们习惯于存储从较低级别推出的信息 - 例如,AMD 的 Zen 2 处理器使用 L3 受害者缓存,该缓存仅存储来自 L2 的数据。 (编辑:ASP站长网) |



 苹果iPhone 13 Pro机
苹果iPhone 13 Pro机 广西电信与中兴通讯完
广西电信与中兴通讯完 小白智能看护灯评测:
小白智能看护灯评测: 专访小米AIoT高管:通
专访小米AIoT高管:通 移动专区周级收录如何
移动专区周级收录如何