MySQL 5.6中的字符集
发布时间:2022-07-05 11:35 所属栏目:115 来源:互联网
导读:
导读:这篇文章介绍的是MySQL 5.6中的字符集,基本是我以前学习MySQL 5.6手册时整理而来。 概论 基础概念 字符集(character set)是编码和字符符号的映射集合。排序规则(collation)是用于比较字符集中字符的规则集。 现在我们自定义一个简单的字符集character set。
|
这篇文章介绍的是MySQL 5.6中的字符集,基本是我以前学习MySQL 5.6手册时整理而来。 概论 基础概念 字符集(character set)是编码和字符符号的映射集合。排序规则(collation)是用于比较字符集中字符的规则集。 现在我们自定义一个简单的字符集character set。假设我们有一个仅有四个字母的字母表:A、B、a、b。我们给每个字母一个数字:A = 0,B = 1,a = 2,b = 3。字母A是一个字符符号,数字0是A的编码,这四个字母和它们编码的映射就是一个字符集。 假设我们想要比较两个字符串的值:A和B。最简单的办法就是查看它们的编码:A的编码为0,B的编码为1。因为0小于1,我们说A小于B。我们所做的就是应用排序规则到字符集。这些规则的集合(在该示例中只有一条规则)就是排序规则collation:比较它们的编码。当然,现实中的字符集和排序规则要复杂地多,但基本理念是上面所说的那样。 repertoire是指一个字符集中字符的集合。字符串表达式都有一个repertoire属性,这个属性可以有两个值: ASCII:表达式只能包含Unicode编码在U+0000到U+007F范围内的字符。 UNICODE:表达式可以包含Unicode编码在U+0000到U+10FFFF范围内的字符。这包括那些在Basic Multilingual Plane(BMP)范围内(U+0000 到 U+FFFF)的字符,和在BMP范围外(U+01000 到 U+10FFFF)的增补字符。 ASCII范围是UNICODE范围的一个子集,因此,一个ASCII repertoire的字符串可以安全地转换成UNICODE repertoire字符串的字符集(或任何包含ASCII范围的字符集),而不会有任何问题。从这里我们可以得到两个结论: 1、特定的字符集拥有特定范围的repertoire,这就限定了使用该字符集的表/字段也就只能使用特定范围的字符,超出范围的字符将不会被那个字符集所支持。比如,ascii字符集的repertoire范围就是ASCII,因此,若使用该字符集,就只能使用Unicode编码在U+0000到U+007F范围内的字符。 2、字符子集的字符集可以安全地转换成它的超集的字符集,而不会有任何问题。这点在不同字符集混用时很有用,MySQL可以完成自动转换。但是,反过来是不行的。 MySQL中的的常见字符集: utf8字符集:是一种UTF-8编码的Unicode字符集,每个字符占用1到3个字节。只能覆盖BMP范围内的字符,其中不单单有英文字符,也包括中文字符等。 utf8mb4字符集:是一种UTF-8编码的Unicode字符集,每个字符占用1到4个字节。可以覆盖BMP范围内的字符和增补字符。BMP范围内的字符编码和utf8字符集中的编码是完全相同的,长度也是完全一样的,所以utf8mb4字符集可以兼容utf8字符集。 元数据的字符集 元数据(Metadata)是"关于数据的数据"。任何描述数据库的东西 — 与数据库中的内容相对,都是元数据。因此,列名、数据库名、用户名、版本名和SHOW命令的大多数字符串结果都是元数据。这对于information_schema库中表的内容也同样正确,因为从定义上来说,那些表包含关于数据库对象的信息。元数据的呈现必须满足这些要求: 所有的元数据都必须使用相同的字符集。否则,对information_schema库中的表执行SHOW或SELECT命令将无法正常运行,因为这些操作返回的结果中,同一列的不同行将会在不同的字符集中。 元数据必须包含所有语言的所有字符。否则,用户将无法使用它们自己本地的语言来被表或列命名。 为了满足上面的要求,MySQL将元数据存储在Unicode字符集中,准确地说是UTF-8。只要你不使用方言或非拉丁字符,这不会有任何问题。但如果你使用了,你应该意识到元数据是UTF-8字符集的。 MySQL将系统变量character_set_system的值设置为与元数据所使用的字符集的相同: mysql> SHOW VARIABLES LIKE 'character_set_system'; +-----------------------+----------+ | Variable_name | Value | +-----------------------+----------+ | character_set_system | utf8 | +-----------------------+---------+ 元数据的存储使用Unicode并不意味着,服务器返回DESCRIBE函数的结果的列名时默认会使用character_set_system变量所设置的字符集。当你使用SELECT column1 FROM t命令时,服务器返回给客户端的column1这个列名自身的字符集,是由系统变量character_set_results的值决定的,默认值是latin1: mysql> SHOW VARIABLES LIKE 'character_set_results'; +-----------------------+---------+ | Variable_name | Value | +-----------------------+---------+ | character_set_results | latin1 | +-----------------------+---------+ 如果你想要服务器返回元数据给客户端时使用不同的字符集,就使用SET NAMES'character_set' 命令来强制服务器将当前字符集转换成指定的character_set,该命令会自动设置character_set_results等相关的系统变量,仅对当前会话生效。如果character_set_results被设为NULL,服务器返回元数据时将不进行转换,而使用它原本的字符集(即变量character_set_system所指示的字符集)。 另外,客户端程序也可以在接收到服务器返回的数据后执行字符集转换。在客户端执行字符集转换效率更高,但并不是所有客户端都支持这个功能。 从上面的说明可以看出,字符集问题不单单影响数据存储,还会影响客户端与MySQL服务器之间的通信。如果你想要让客户端程序使用与默认字符集不相同的字符集与服务器端通信,你需要指明哪一个。比如,要使用 utf8 字符集,执行命令: mysql> SET NAMES 'utf8'; 当然,因为还没有再MySQL配置文件中设置相关变量,所以这里的设置并不是持久的。仅在当前会话中生效。  存储数据时的字符集 MySQL支持在MySQL服务器(server)、数据库(database)、表(table)和列(column)四个级别指定所使用的字符集。MySQL支持对MyISAM、MEMORY和InnoDB存储引擎配置字符集。 1、 MySQL服务器有一个服务器字符集和服务器排序规则,分别由变量character_set_server和变量collation_server控制。你可以在MySQL配置文件中或MySQL启动选项中设置这两个选项的值,也支持使用set命令进行动态修改,有全局值和会话值两种。character_set_server的默认值是latin1字符集,collation_server的默认值是latin1_swedish_ci排序规则。如果你只指定了字符集,而没有指定排序规则,那么系统会自动将排序规则设置为该字符集的默认排序规则。比如,如果你将character_set_server的值设置为utf8mb4字符集而没有设置collation_server的值,那么collation_server的值会自动变为utf8mb4_general_ci排序规则,因为utf8mb4_general_ci是utf8mb4字符集的默认排序规则。 [root@gw ~]# vim /usr/my.cnf [mysqld] character-set-server=utf8mb4 collation-server=utf8mb4_general_ci 在使用CREATE DATABASE命令创建数据库时如果没有指定数据库字符集和排序规则, 那么服务器端字符集和排序规则就会作为默认值,它们的用途仅在于这里。因此可以说,服务器端字符集和排序规则是MySQL数据库中数据(除元数据外)的可能的默认值。 2、 MySQL中的每一个库都有一个数据库字符集和数据库排序规则。CREATE DATABASE 和 ALTER DATABASE语句都有选项可以指定数据库字符集和排序规则: CREATE DATABASE db_name [[DEFAULT] CHARACTER SET charset_name] [[DEFAULT] COLLATE collation_name] ALTER DATABASE db_name [[DEFAULT] CHARACTER SET charset_name] [[DEFAULT] COLLATE collation_name] MySQL按照下面的方式决定数据库的字符集和排序规则: 如果CHARACTER SETcharset_name和COLLATEcollation_name都指定了,那么数据库字符集和排序规则就是所指定的charset_name和collation_name。 如果只指定了CHARACTER SETcharset_name而没有指定COLLATE,那么数据库字符集和排序规则就是所指定的charset_name和该字符集默认的排序规则。 如果只指定了COLLATEcollation_name而没有指定CHARACTER SET,那么数据库字符集和排序规则就是该collation_name相关联的字符集和所指定的collation_name。 如果CHARACTER SETcharset_name和COLLATEcollation_name都没有指定,那么数据库字符集和排序规则就使用MySQL服务器字符集和排序规则(见上一小节)。 数据库默认字符集和排序规则可以从character_set_database 和 collation_database这两个系统变量得知。要查看指定数据库的默认字符集和排序规则,使用命令: mysql> use db_name; mysql> SELECT @@character_set_database, @@collation_database; 也可以使用下面的命令: mysql> SELECT DEFAULT_CHARACTER_SET_NAME, DEFAULT_COLLATION_NAME FROM INFORMATION_SCHEMA.SCHEMATA WHERE SCHEMA_NAME = 'db_name'; 数据库字符集和排序规则影响服务器运行的这些方面: 对于CREATE TABLE语句,如果创建表时未显式指定字符集和排序规则,数据库字符集和排序规则被用做表的默认字符集和排序规则。要覆盖该行为,显式使用CHARACTER SET 和 COLLATE选项。 对于不包括CHARACTER SET选项的LOAD DATA语句,服务器使用变量character_set_database所指示的字符集来解析文件中的信息。要覆盖该行为,显式使用CHARACTER SET选项。 对于存储的程序(过程和函数),在创建程序时如果字符数据参数(character data parameters)的声明未使用CHARACTER SET 和 COLLATE选项,那么数据库字符集和排序规则会用做字符数据参数的字符集和排序规则。要覆盖该行为,显式使用CHARACTER SET 和 COLLATE选项。 3、 每个表都有一个表字符集和表排序规则。CREATE TABLE 和 ALTER TABLE语句都有选项可以指定表字符集和排序规则: CREATE TABLE tbl_name (column_list) [[DEFAULT] CHARACTER SET charset_name] [COLLATE collation_name]] ALTER TABLE tbl_name [[DEFAULT] CHARACTER SET charset_name] [COLLATE collation_name] 示例: CREATE TABLE t1 ( ... ) CHARACTER SET latin1 COLLATE latin1_danish_ci; MySQL按照下面的方式决定表的字符集和排序规则: 如果CHARACTER SETcharset_name和COLLATEcollation_name都指定了,那么表字符集和排序规则就是所指定的charset_name和collation_name。 如果只指定了CHARACTER SETcharset_name而没有指定COLLATE,那么表字符集和排序规则就是所指定的charset_name和该字符集默认的排序规则。 如果只指定了COLLATEcollation_name而没有指定CHARACTER SET,那么表字符集和排序规则就是该collation_name相关联的字符集和所指定的collation_name。 如果CHARACTER SETcharset_name和COLLATEcollation_name都没有指定,那么表字符集和排序规则就使用数据库字符集和排序规则(见上一小节)。 表字符集和排序规则被用作列定义中的默认值,如果在单个的列定义中没有指定列字符集和排序规则。表字符集和排序规则是MySQL的扩展,并不是标准SQL中的东西。 4、 每一个"字符"列(即是,CHAR、VARCHAR或TEXT类型的列)都有一个列字符集和列排序规则。CREATE TABLE 和 ALTER TABLE语句中都有选项可以指定列字符集和排序规则: col_name {CHAR | VARCHAR | TEXT} (col_length) [CHARACTER SET charset_name] [COLLATE collation_name] ENUM和SET类型的列中也有选项: col_name {ENUM | SET} (val_list) [CHARACTER SET charset_name] [COLLATE collation_name] 示例: CREATE TABLE t1 ( col1 VARCHAR(5) CHARACTER SET latin1 COLLATE latin1_german1_ci ); ALTER TABLE t1 MODIFY col1 VARCHAR(5) CHARACTER SET latin1 COLLATE latin1_swedish_ci; MySQL按照下面的方式决定列的字符集和排序规则: 如果CHARACTER SETcharset_name和COLLATEcollation_name都指定了,那么列字符集和排序规则就是所指定的charset_name和collation_name。 如果只指定了CHARACTER SETcharset_name而没有指定COLLATE,那么列字符集和排序规则就是所指定的charset_name和该字符集默认的排序规则。 如果只指定了COLLATEcollation_name而没有指定CHARACTER SET,那么列字符集和排序规则就是该collation_name相关联的字符集和所指定的collation_name。 如果CHARACTER SETcharset_name和COLLATEcollation_name都没有指定,那么列字符集和排序规则就使用表字符集和排序规则(见上一小节)。 字符串字面量的字符集 除了前面所说的,每一个字符串字面量(string literal)都有一个字符集和排序规则。对于简单语句SELECT 'string',这里用到的string有一个连接默认字符集和排序规则(connection default character set and collation),分别由系统变量character_set_connection和collation_connection控制。一个字符串字面量可能会有一个可选的字符集introducer和COLLATE子句,来将它指定为使用特定字符集和排序规则的字符串: [_charset_name]'string' [COLLATE collation_name] 示例: SELECT 'abc'; SELECT _latin1'abc'; SELECT _binary'abc'; SELECT _utf8'abc' COLLATE utf8_danish_ci; _charset_name这个表达式的正式叫法叫做introducer。它告诉解析器:它后面所接的字符串使用字符集charset_name。MySQL按照下面的方式决定字符串字面量的字符集和排序规则: 如果_charset_name和COLLATEcollation_name都指定了,那么字符串字面量字符集和排序规则就是所指定的charset_name和collation_name。 如果只指定了_charset_name而没有指定COLLATE,那么字符串字面量字符集和排序规则就是所指定的charset_name和该字符集默认的排序规则。 如果只指定了COLLATEcollation_name而没有指定_charset_name,那么字符串字面量字符集和排序规则就是系统变量character_set_connection所指定的连接默认字符集和所指定的collation_name。collation_name必须是连接默认字符集的排序规则之一。 如果_charset_name和COLLATEcollation_name都没有指定,那么字符串字面量字符集和排序规则就使用系统变量character_set_connection和collation_connection所指定的连接默认字符集和排序规则。 连接相关的字符集 每一个客户端都有一个连接相关的(connection-related)字符集和排序规则。一个"connection"就是指当你连接到MySQL服务器时的连接。客户端发送SQL语句,比如查询,是通过到服务器的连接。服务器返回数据,比如查询结果或错误信息,是通过到客户端的连接。这导致了下面几个与客户端连接相关的字符集和排序规则的问题: 1、 当它离开客户端时语句的字符集是什么? 服务器会将character_set_client系统变量的值当做是客户端所发送的SQL语句的字符集。 2、 服务器在接收到SQL语句后,会将它转换成什么字符集? 服务器会将客户端所发送的SQL语句的字符集,从character_set_client转换成character_set_connection所指向的字符集(除了那些有introducer的字符串字面量)。字符串字面量的比较则使用collation_connection所指向的排序规则。对于那些有列值的字符串的比较,则与collation_connection没什么关系,因为列有它们自己的排序规则,那个排序规则的优先级更高。 3、 服务器在将SQL查询结果或错误信息发送回给客户端之前会将它们转换成什么字符集? 服务器会将SQL查询结果的字符集转换成系统变量character_set_results所指向的字符集。要转换的数据包括列值和元数据(比如列名和错误信息)。 有两个命令可以统一设置连接相关的字符集: 1、 SET NAMES命令 SET NAMES命令告诉MySQL服务器,客户端使用的是什么字符集与它交互的。SET NAMES命令设置的值只会对当前会话生效。语法格式: SET NAMES 'charset_name' [COLLATE 'collation_name'] 一条 SET NAMES 'charset_name' 语句(COLLATE 'collation_name'是可选的)实际上等同于下面的三条语句: SET character_set_client = charset_name; SET character_set_results = charset_name; SET character_set_connection = charset_name; // 这第三条语句也隐含了将变量collation_connection设置为charset_name字符集默认的排序规则 2、 SET CHARACTER SET命令 SET CHARACTER SET命令类似于SET NAMES,但将character_set_connection和collation_connection设置为character_set_database和collation_database。语法格式: SET CHARACTER SET charset_name; 一条 SET CHARACTER SET charset_name 命令实际上等同于下面的三条语句: SET character_set_client = charset_name; SET character_set_results = charset_name; SET collation_connection = @@collation_database; // 这第三条语句也隐含了执行命令SET character_set_connection = @@character_set_database; 对于MySQL客户端程序mysql、mysqladmin、mysqlcheck、mysqlimport和mysqlshow,它们是按照下面的规则来决定与MySQL服务器端通信时所使用的字符集的: 1、 在缺少其它信息的情况下,它们会使用预设的默认字符集(通常是latin1)来与MySQL服务器端通信。这个预设的默认字符集也可以在MySQL配置文件中使用下面选项指定: [root@gw ~]# vim /usr/my.cnf [client] default-character-set=utf8mb4 2、 程序可以自动检测要使用哪一个字符集,基于操作系统设置,比如LANG或LC_ALL环境变量的值。比如,如果操作系统中LANG环境变量的值为ru_RU.KOI8-R,会使得这些客户端程序变成使用koi8r字符集。这一点会比第1点优先。 3、 这些程序支持使用选项 --default-character-set 来让用户显式指定字符集,以覆盖程序自动决定的字符集。这一点会比第1、2点都优先。 如果你想要服务器在返回SQL查询结果或错误信息给客户端时不执行字符集转换,可以将character_set_results变量设为NULL或binary: SET character_set_results = NULL; 查看字符集 要显示MySQL中所支持的所有字符集,可以查看information_schema.character_sets表或使用show character set命令,后面可以加上 LIKE 或 WHERE子句进行过滤: mysql> SHOW CHARACTER SET; mysql> select * from information_schema.character_sets; 一个给定的字符集至少会有一个排序规则。大多数的字符集支持多个排序规则,其中一个是默认的。要显示字符集所支持的所有排序规则,可以查看information_schema.collations表或使用show collation命令,后面可以加上 LIKE 或 WHERE子句进行过滤: mysql> SHOW COLLATION; mysql> select * from information_schema.collations; 如果要使用所有跟字符集和排序规则相关的系统变量,可以使用命令: mysql> SHOW VARIABLES WHERE Variable_name LIKE 'character_set%' OR Variable_name LIKE 'collation%'. (编辑:ASP站长网) |
相关内容
 MySQL IS NULL如何查
MySQL IS NULL如何查 最简单的创建 MySQL
最简单的创建 MySQL 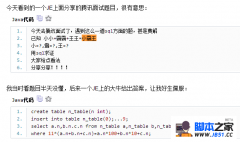 网上看到的给大家分享
网上看到的给大家分享 MYSQL教程MySql 5.6.3
MYSQL教程MySql 5.6.3网友评论
推荐文章
热点阅读