MySQL的高级部分
发布时间:2022-07-05 11:39 所属栏目:115 来源:互联网
导读:MySQL的事务 (1)存储引擎的介绍 介绍:当客户端发送一条SQL语句给服务器时,服务器端通过缓存、语法检查、校验通过之后,然后会通过调用底层的一些软件组织,去从数据库中查询数据,然后将查询到的结果集返回给客户端,而这些底层的软件组织就是存储引擎。
|
MySQL的事务 (1)存储引擎的介绍 介绍:当客户端发送一条SQL语句给服务器时,服务器端通过缓存、语法检查、校验通过之后,然后会通过调用底层的一些软件组织,去从数据库中查询数据,然后将查询到的结果集返回给客户端,而这些底层的软件组织就是存储引擎。 MySQL的存储引擎: - MySQL的核心就是存储引擎,MySQL可以设置多种不同的存储引擎,不同的存储引擎在索引、存储、以及锁的策略上是不同的。 - Mysql5.5之前,使用的是myisam存储引擎,支持全文搜索,不支持事务。 - Mysql5.5以后,使用的是innodb存储引擎,支持事务以及行级锁 MySQL的高级部分 (2)MySQL事务的介绍 介绍:事务是一个操作序列,这些操作要么都做,要么都不做,是一个不能分割的工作单位。在两条或两条以上的SQL语句才能完成的业务时,才需要用事务,因为事务时同步原则,效率比较低。 事务的ACID特性: - 原子性:放在同一事务的一组操作时不可分割的 - 一致性:在事务的执行前后,整体的状态是不变的 - 隔离性:事务之间是独立存在的,两个不同事务之间互不影响 - 持久性:事务执行之后,将会永久的影响到数据库。 #例:一个事务操作 BEGIN; update t_account set money=money+100 where id =1; update t_account set money=money-100 where id =2; COMMIT; #一个回滚操作 BEGIN; update t_account set money=money+100 where id =1; update t_account set money=money-100 where id =2; COMMIT; 注意:MySQL数据库,dml操作采用的是自动提交 #查看自动提交 show variables like 'autocommit'; #修改自动提交 set autocommit=0; (3)MySQL事务并发时产生的问题 脏读:在一个事务的执行范围内,读到了另一事务未提交的数据。 解决:读已提交,一个数据库只能读到另一个事务提交后的数据。(Oracle默认的事务隔离级别) 不可重复读:一个事务,在只读范围内,被另一事务修改并提交事务,导致多次读取的数据不一致的问题。 解决:可重复读(MySQL默认的事务隔离级别) 虚读:一个事务的只读范围内,被另一个事务删除或者添加数据,导致多次读取的数据不一致的问题。 解决:串行化:解决所有问题,但是速度十分缓慢,不能使用并发事务。 注意:查看事务的隔离级别:select @@tx_isolation; 2. MySQL的存储程序 (1)MySQL的存储程序的介绍 描述:运行与服务器端的程序。 优点:简化开发,执行效率比较高(在服务器端以通过校验,可直接使用) 缺点:服务器端保存这些存储程序需要占用磁盘空间;数据迁移时,需要将这些存储程序进行迁移;调试和编写程序在服务器端都不方便 存储程序的分类:存储过程、存储函数、触发器 注意:存储程序不能使用事务 (2)存储过程 介绍:存储过程是在服务器端的一段可执行的代码块。 例: #修改结束符标志 delimiter // #创建存储过程 create procedure pro_book() begin #sql select * from book; select * from book where bid=3; end // #运行 call pro_book() #参数的传入 delimiter // create procedure pro_book02(num int) begin select * from book where bid=num; end ; // --调用 call pro_book02(3) #传出参数 delimiter // create procedure pro_book03(num int,out v_name varchar(10)) begin select bname into v_name from book where bid=num; end ; // --调用,这里的@v_name是一个用户变量 call pro_book03(1,@v_name); select @v_name; #传入传出参数 delimiter // create procedure pro_book04(num int) begin select bid into num from book where bid=num; end ; // --调用 set @v_id=3; --给用户变量赋值 call pro_book04(@v_id); select @v_id; 控制流程语句 #if语句 delimiter // create procedure if_test(score int) begin -- 定义局部变量 declare myLevel varchar(20); if score>80 then set myLevel='A'; elseif score >60 then set myLevel='B'; else set myLevel='C'; end if; select myLevel; end; // -- 调用 call if_test(70); #while循环 delimiter // create procedure while_test() begin declare i int ; declare sum int ; set i=1; set sum =0; while i<=100 do set sum=sum+i; set i=i+1; end while ; select sum; end ;// call while_test() #loop循环 delimiter // create procedure loop_test() begin declare i int ; declare sum int ; set i=1; set sum =0; -- 起别名 lip:loop if i>100 then -- 离开loop循环 leave lip ; end if ; set sum=sum+i; set i=i+1; end loop ; select sum; end ;// call loop_test() #repeat循环 delimiter // create procedure repeat_test() begin declare i int ; declare sum int ; set i=1; set sum =0; repeat set sum=sum+i; set i=i+1; -- 不要加分号 until i>100 end repeat ; select sum; end ;// call loop_test() (3)存储函数 存储在服务器端,有返回值,函数可以作为SQL的一部分进行调用。 **例**: delimiter // create function func_01(num int) -- 返回值类型 returns varchar(20) deterministic begin declare v_name varchar(20); select bname into v_name from book where bid =num ; return v_name; end ; // set @v_name=func_01(3); select @v_name; -- 作为SQL的一部分调用 select * from book where bname=func_01(3); 函数和存储过程的区别: - 存储过程有三种参数模式(in、out、inout)实现数据的输入输出,而函数是通过返回值进行数据传递。 - 关键字不同 - 存储过程可以作为独立个体执行,函数只能作为SQL的一部分执行。 (4)触发器 触发器,存储在服务器端,由事件调用,不能传参。 事件类型:增、删、改 语法: create trigger 触发器名 触发时机(after|before) event(update|delete|insert) on 需要设置触发器的表名 for each row (设置为行级触发器) begin 一组sql end; 例: delimiter //; -- 创建一个触发器 create trigger tri_test after delete -- 设置为行级别的触发器 on book for each row begin insert into book values(old.id,'悲惨数据','zzy'); end;// 注意:在触发器中有两个对象:old、new,old表示删除数据时那条原数据记录, new表示修改和插入数据时,那条新数据记录。 3. MySQL的表的设计 (1)数据库的三大范式: - 1NF:所有字段都是原子性的,不可分割的。 - 2NF:非主键字段必须与主键相关(每一张表只描述一类事物),而不能与主键部分相关(在联合主键时有效) - 3NF:非主键字段必须与主键相关(每一张表只描述一类事物),而不能与主键部分相关(在联合主键时有效) (2)表的关系: 一一对应 #以人和×××为例 人表: CREATE TABLE `t_people` ( `id` int(11) NOT NULL, `name` varchar(50) DEFAULT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ×××表: create table t_idcard( card_number varchar(18) primary key, create_date date, p_id int unique, foreign key (p_id) REFERENCES t_people(id) ) 注意:设计方法:想办法让外键字段同时拥有唯一约束,外键字段在任意的表中都可以 一对多: 以部门和员工表为例: create table t_emp( eid int PRIMARY KEY, ename varchar(50) not null, job varchar(50), deptno int , foreign key (deptno) REFERENCES t_dept(deptno) ) 部门表: create table t_dept( deptno int primary key, deptname varchar(50) ) 注意:设计方法:只需要在多的那个表中增加一个外键约束 多对多: MySQL的高级部分 设计方法:需要找一张中间表,转化成两个一对多的关系 (3)数据库的优化: SQL的优化 在查询时一般不使用 *,因为在查询记录时,一般使用(*),他会将*转换为列名,然后在查询(耗时) 使用 not null /null 对索引进行搜索,会导致索引失效 索引列中使用函数,也会导致索引失效 索引列中进行计算,也会导致索引失效 索引列不要使用not|!=|<> 尽量不要使用or,使用union 索引列中使用like,也会导致索引失效 exists 和 in的使用选择 exists先执行主查询:如果主查询过滤的比较多,则使用exists in先执行子查询:如果是子查询的过滤比较多,则使用in。 (编辑:ASP站长网) |
相关内容
 MySQL IS NULL如何查
MySQL IS NULL如何查 最简单的创建 MySQL
最简单的创建 MySQL 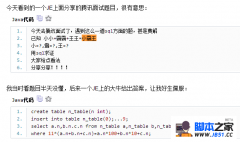 网上看到的给大家分享
网上看到的给大家分享 MYSQL教程MySql 5.6.3
MYSQL教程MySql 5.6.3网友评论
推荐文章
热点阅读