Redis缓存三大问题解析,看完保你面试能造火箭,工作能拧螺丝。(2)
|
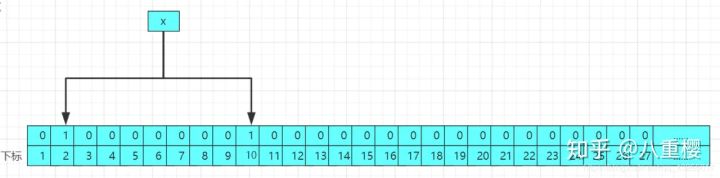
以上只是画了布隆过滤器的很小很小的一部分,实际布隆过滤器是非常大的数组(这里的大是指它的长度大,并不是指它所占的内存空间大)。 那么一个数据是怎么存进布隆过滤器的呢? 当一个数据进行存入布隆过滤器的时候,会经过如干个哈希函数进行哈希(若是对哈希函数还不懂的请参考这一片[]),得到对应的哈希值作为数组的下标,然后将初始化的位数组对应的下标的值修改为1,结果图如下: ?
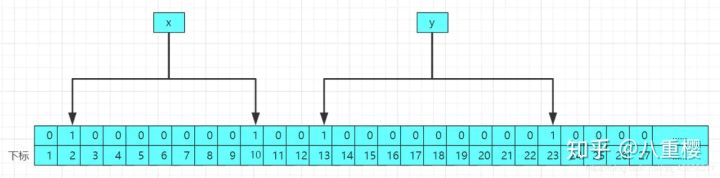
? 当再次进行存入第二个值的时候,修改后的结果的原理图如下:
所以每次存入一个数据,就会哈希函数的计算,计算的结果就会作为下标,在布隆过滤器中有多少个哈希函数就会计算出多少个下标,布隆过滤器插入的流程如下:
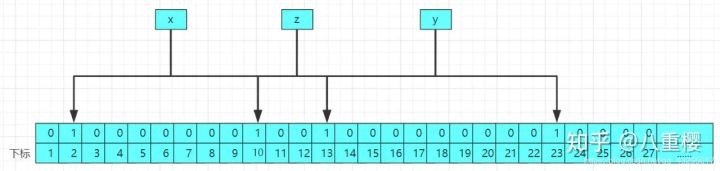
那么为什么会有误判率呢? 假设在我们多次存入值后,在布隆过滤器中存在x、y、z这三个值,布隆过滤器的存储结构图图如下所示:
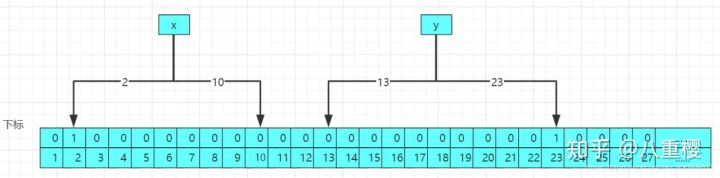
当我们要查询的时候,比如查询a这个数,实际中a这个数是不存在布隆过滤器中的,经过2哥哈希函数计算后得到a的哈希值分别为2和13,结构原理图如下:
经过查询后,发现2和13位置所存储的值都为1,但是2和13的下标分别是x和z经过计算后的下标位置的修改,该布隆过滤器中实际不存在a,那么布隆过滤器就会误判改值可能存在,因为布隆过滤器不存元素值,所以存在误判率。 那么具体布隆过布隆过滤的判断的准确率和一下两个因素有关:
那么为什么不能删除元素呢? 原因很简单,因为删除元素后,将对应元素的下标设置为零,可能别的元素的下标也引用改下标,这样别的元素的判断就会收到影响,原理图如下:
当你删除z元素之后,将对应的下标10和13设置为0,这样导致x和y元素的下标受到影响,导致数据的判断不准确,所以直接不提供删除元素的api。 以上说的都是布隆过滤器的原理,只有理解了原理,在实际的运用才能如鱼得水,下面就来实操代码,手写一个简单的布隆过滤器。 对于要手写一个布隆过滤器,首先要明确布隆过滤器的核心:
实现得代码如下: public class MyBloomFilter {
// 布隆过滤器长度
private static final int SIZE = 2 << 10;
// 模拟实现不同的哈希函数
private static final int[] num= new int[] {5,19,23,31,47,71};
// 初始化位数组
private BitSet bits = new BitSet(SIZE);
// 用于存储哈希函数
private MyHash[] function = new MyHash[num.length];
// 初始化哈希函数
public MyBloomFilter() {
for (int i = 0; i < num.length; i++) {
function [i] = new MyHash(SIZE,num[i]);
}
}
// 存值Api
public void add(String value) {
// 对存入得值进行哈希计算
for (MyHash f: function) {
// 将为数组对应的哈希下标得位置得值改为1
bits.set(f.hash(value),true);
}
}
// 判断是否存在该值得Api
public boolean contains(String value) {
if (value == null) {
return false;
}
boolean result= true;
for (MyHash f : func) {
result= result&& bits.get(f.hash(value));
}
return result;
}
}
(编辑:ASP站长网) |


 怎样利用智能技术建设
怎样利用智能技术建设 如果传感器出现故障,
如果传感器出现故障,