Redis缓存三大问题解析,看完保你面试能造火箭,工作能拧螺丝。(3)
发布时间:2020-12-25 04:38 所属栏目:31 来源:网络整理
导读:哈希函数代码如下: public static class MyHash { private int cap; private int seed; // 初始化数据 public MyHash(int cap,int seed) { this.cap = cap; this.seed = seed; } // 哈希函数 public int hash(Stri
|
哈希函数代码如下: public static class MyHash {
private int cap;
private int seed;
// 初始化数据
public MyHash(int cap,int seed) {
this.cap = cap;
this.seed = seed;
}
// 哈希函数
public int hash(String value) {
int result = 0;
int len = value.length();
for (int i = 0; i < len; i++) {
result = seed * result + value.charAt(i);
}
return (cap - 1) & result;
}
}
布隆过滤器测试代码如下: public static void test {
String value = "4243212355312";
MyBloomFilter filter = new MyBloomFilter();
System.out.println(filter.contains(value));
filter.add(value);
System.out.println(filter.contains(value));
}
以上就是手写了一个非常简单得布隆过滤器,但是实际项目中可能事由牛人或者大公司已经帮你写好的,如谷歌的 <dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>27.0.1-jre</version>
</dependency>
实际项目中具体的操作代码如下: public static void MyBloomFilterSysConfig {
@Autowired
OrderMapper orderMapper
// 1.创建布隆过滤器 第二个参数为预期数据量10000000,第三个参数为错误率0.00001
BloomFilter<CharSequence> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.forName("utf-8")),10000000,0.00001);
// 2.获取所有的订单,并将订单的id放进布隆过滤器里面
List<Order> orderList = orderMapper.findAll()
for (Order order;orderList ) {
Long id = order.getId();
bloomFilter.put("" + id);
}
}
在实际项目中会启动一个系统任务或者定时任务,来初始化布隆过滤器,将热点查询数据的id放进布隆过滤器里面,当用户再次请求的时候,使用布隆过滤器进行判断,改订单的id是否在布隆过滤器中存在,不存在直接返回null,具体操作代码: // 判断订单id是否在布隆过滤器中存在
bloomFilter.mightContain("" + id)
布隆过滤器的缺点就是要维持容器中的数据,因为订单数据肯定是频繁变化的,实时的要更新布隆过滤器中的数据为最新。 缓存击穿缓存击穿是指一个 缓存击穿这里强调的是并发,造成缓存击穿的原因有以下两个:
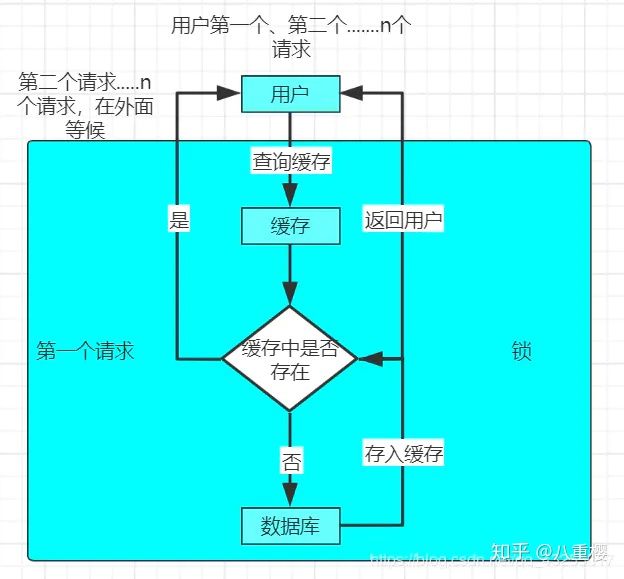
对于缓存击穿的解决方案就是加锁,具体实现的原理图如下:
当用户出现大并发访问的时候,在查询缓存的时候和查询数据库的过程加锁,只能第一个进来的请求进行执行,当第一个请求把该数据放进缓存中,接下来的访问就会直接集中缓存,防止了缓存击穿。 业界比价普遍的一种做法,即根据key获取value值为空时,锁上,从数据库中 ? 下面以一个获取商品库存的案例进行代码的演示,单机版的锁实现具体实现的代码如下: // 获取库存数量
public String getProduceNum(String key) {
try {
synchronized (this) { //加锁
// 缓存中取数据,并存入缓存中
int num= Integer.parseInt(redisTemplate.opsForValue().get(key));
if (num> 0) {
//没查一次库存-1
redisTemplate.opsForValue().set(key,(num- 1) + "");
System.out.println("剩余的库存为num:" + (num- 1));
} else {
System.out.println("库存为0");
}
}
} catch (NumberFormatException e) {
e.printStackTrace();
} finally {
}
return "OK";
}
(编辑:ASP站长网) |
相关内容
 怎样利用智能技术建设
怎样利用智能技术建设 如果传感器出现故障,
如果传感器出现故障,网友评论
推荐文章
热点阅读